.NET程序的對(duì)象是由CLR控制并分配在托管堆中,如果是你,會(huì)如何設(shè)計(jì)一個(gè)內(nèi)存分配策略呢?
按需分配,要多少分配多少,移動(dòng)alloc_ptr指針即可,沒有任何浪費(fèi)。缺點(diǎn)是每次都要向OS申請(qǐng)內(nèi)存,效率低
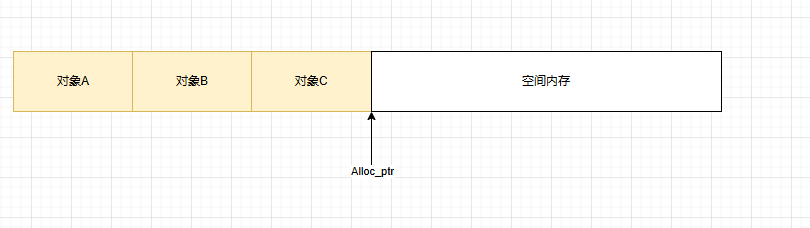
預(yù)留緩沖區(qū),降低了向OS申請(qǐng)內(nèi)存的頻次。但在多線程情況下,alloc_ptr鎖競(jìng)爭(zhēng)會(huì)非常激烈,同樣會(huì)降低效率
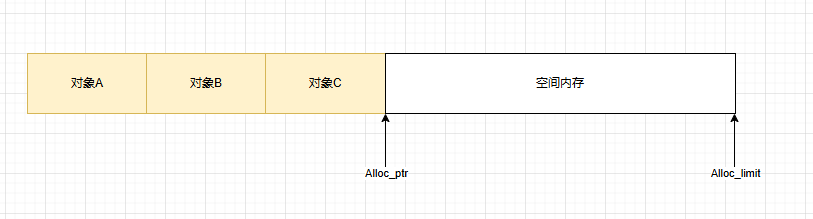
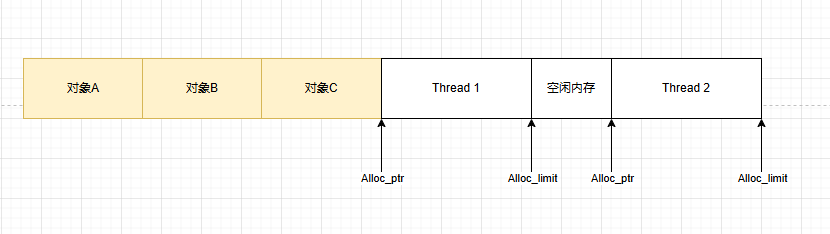
利用TLS,來(lái)避免鎖競(jìng)爭(zhēng),但Thread1與Thread2之間存在Free塊,內(nèi)存空間浪費(fèi)多。
將Free塊利用起來(lái),實(shí)現(xiàn)最大化能效
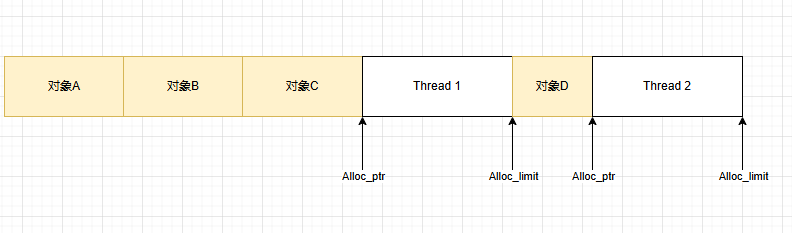
.NET程序就是采用了第四種,來(lái)實(shí)現(xiàn)空間與時(shí)間的最大化。
因此有些alloc_context在段尾,有些在兩個(gè)已分配對(duì)象之間的空余空間
眼見為實(shí)
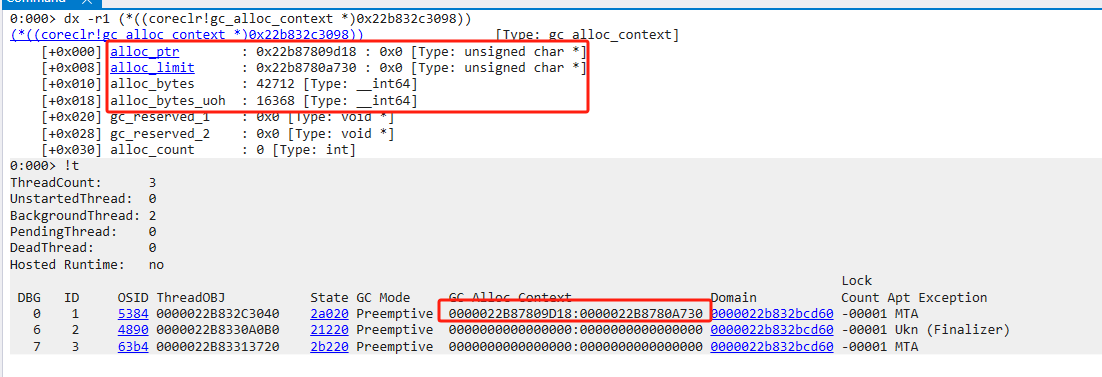

Free塊
在上面,我們已經(jīng)見到了Free塊,簡(jiǎn)單來(lái)說(shuō),F(xiàn)ree就是segment中留下來(lái)的空洞。也就是內(nèi)存碎片。
Free塊產(chǎn)生的原因主要有三種
- GC計(jì)劃階段,用作特殊目的
- GC標(biāo)記階段,將垃圾對(duì)象標(biāo)記為Free
- 多個(gè)Free相鄰時(shí),GC將多個(gè)合并為一個(gè)大的Free塊
內(nèi)存碎片的危害:造成內(nèi)存空間的浪費(fèi),降低內(nèi)存分配效率。
眼見為實(shí)
點(diǎn)擊查看代碼
internal class Program
{
public static byte[] bytes1, bytes2, bytes3, bytes4, bytes5, bytes6;
static void Main(string[] args)
{
Alloc();
Console.WriteLine("分配完畢");
Debugger.Break();
GC.Collect();
Console.WriteLine("GC完成");
Debugger.Break();
}
public static void Alloc()
{
bytes1 = new byte[85000];
bytes2 = new byte[85000];
bytes3 = new byte[85000];
bytes4 = new byte[85000];
bytes5 = new byte[85000];
bytes6 = new byte[85000];
bytes2 = null;
bytes3 = null;
bytes5 = null;
}
}
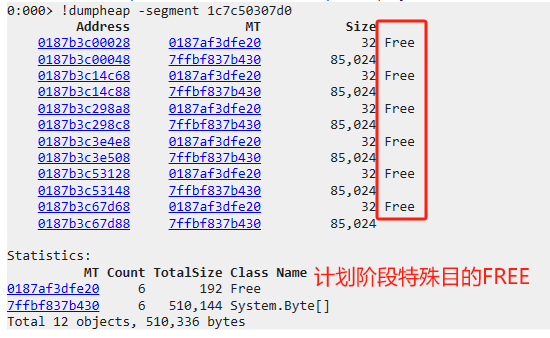
LOH特有的特殊標(biāo)記
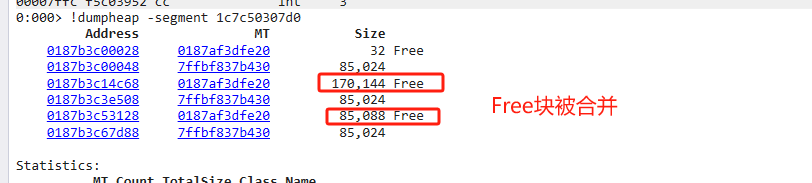
垃圾對(duì)象被標(biāo)記為Free,相鄰的Free對(duì)象合并。
Free塊管理邏輯
CLR對(duì)Free塊采用數(shù)組+鏈表進(jìn)行管理,根據(jù)size確定對(duì)應(yīng)的bucket,再使用雙向鏈表維系大小相近的Free塊。
這樣按照大小維度劃分,極大提高了查找的性能,拿空間換時(shí)間。
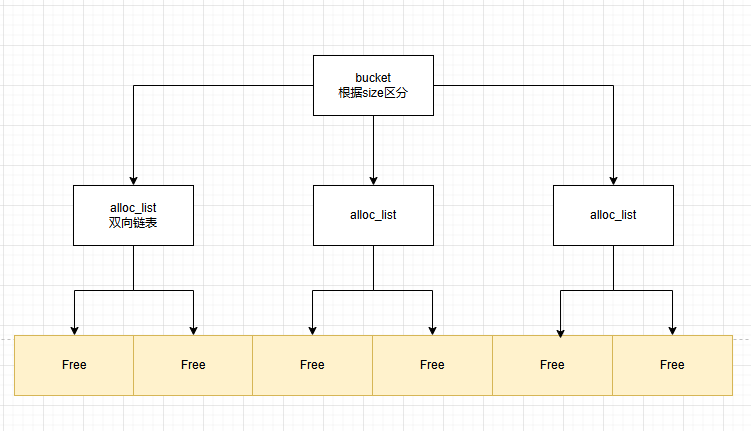
眼見為實(shí)
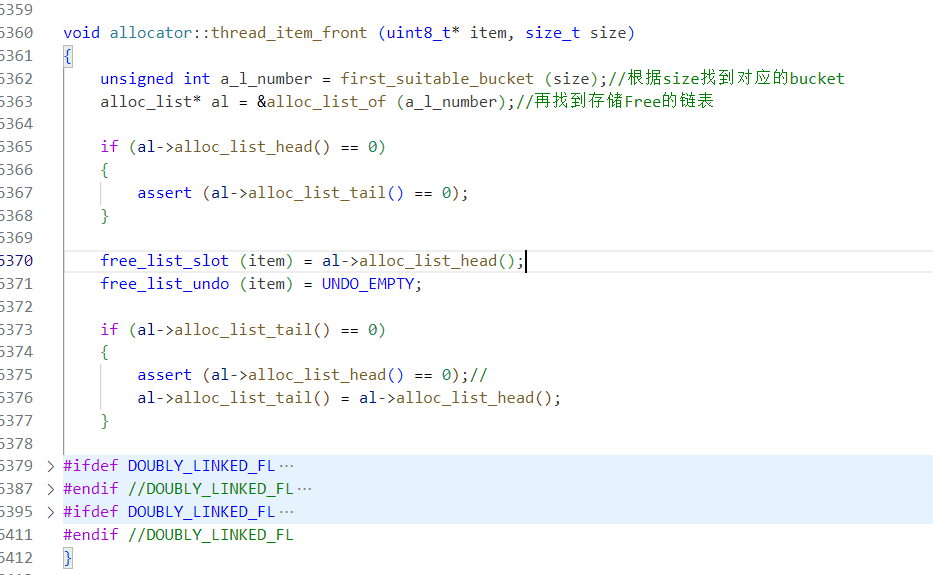
不是所有Free都會(huì)被納入管理,只有 free > 2 * min_obj_size 的對(duì)象才能進(jìn)入bucket集合中,可以思考一下為什么會(huì)這么做。
Free塊內(nèi)存結(jié)構(gòu)
與其它普通對(duì)象類似,也有對(duì)象頭與方法表,再附加額外信息。內(nèi)存結(jié)構(gòu)如下。

眼見為實(shí)
點(diǎn)擊查看代碼
internal class Program
{
public static byte[] bytes1, bytes2, bytes3, bytes4, bytes5, bytes6;
static void Main(string[] args)
{
Alloc();
Console.WriteLine("分配完畢");
Debugger.Break();
GC.Collect();
Console.WriteLine("GC完成");
Debugger.Break();
}
public static void Alloc()
{
bytes1 = new byte[85000];
bytes2 = new byte[85000];
bytes3 = new byte[85000];
bytes4 = new byte[85000];
bytes5 = new byte[85000];
bytes6 = new byte[85000];
bytes2 = null;
bytes4 = null;
bytes6 = null;
}
}
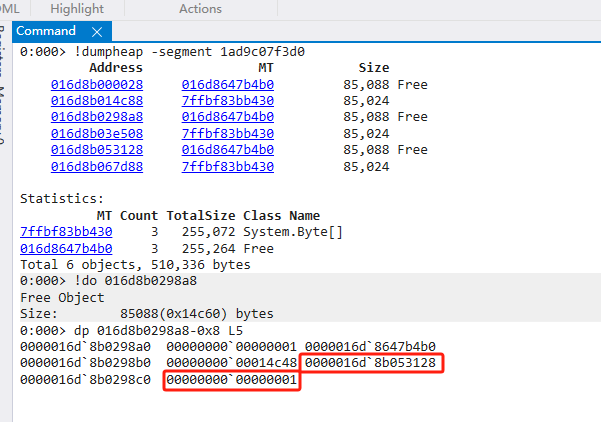
細(xì)心的朋友會(huì)發(fā)現(xiàn)兩個(gè)問題
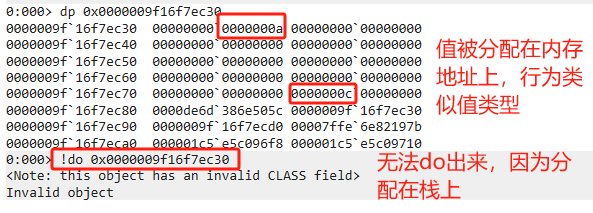
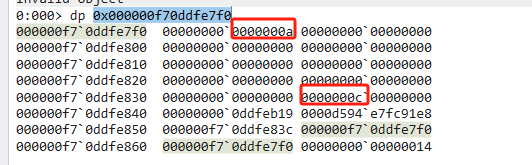
- do命令顯示的size明明為0x14c60,為什么dp命令顯示為0x14c48?
只是計(jì)算取值的差異,它們之間差值為24,分別為objectheader/mt/size - 為什么Next Free有值,Prev Free沒有值?
在SOH上2代Free記錄了Next/Prev Free的雙向鏈表。 其他代只記錄了Next Free的單向鏈表
對(duì)象分配過(guò)程
點(diǎn)擊查看代碼
internal class Program
{
static void Main(string[] args)
{
Debugger.Break();
var person = new Person();
Debugger.Break();
}
}
public class Person
{
private long age = 10;
private int age2 = 10;
private int age3 = 10;
}
new Person() 的匯編如下
00007ffb`93b8195e 48b9d893c393fb7f0000 mov rcx,7FFB93C393D8h (MT: Example_12_1_4.Person)
00007ffb`93b81968 e8d3ceb65f call coreclr!JIT_TrialAllocSFastMP_InlineGetThread (00007ffb`f36ee840)
00007ffb`93b8196d 488945f0 mov qword ptr [rbp-10h],rax
00007ffb`93b81971 488b4df0 mov rcx,qword ptr [rbp-10h]
00007ffb`93b81975 ff15b5df0a00 call qword ptr [00007ffb`93c2f930 (Example_12_1_4.Person..ctor())
00007ffb`93b8197b 488b45f0 mov rax,qword ptr [rbp-10h]
00007ffb`93b8197f 488945f8 mov qword ptr [rbp-8],rax
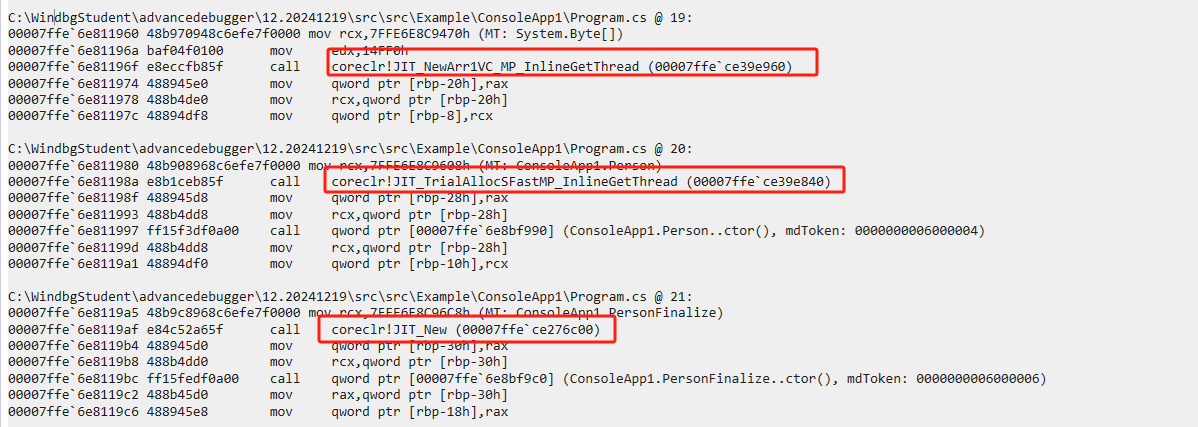
可以看到,New對(duì)象的創(chuàng)建分為兩步:
- 先調(diào)用JIT_TrialAllocSFastMP_InlineGetThread進(jìn)行內(nèi)存分配
LEAF_ENTRY JIT_TrialAllocSFastMP_InlineGetThread, _TEXT
mov edx, [rcx + OFFSET__MethodTable__m_BaseSize]
INLINE_GETTHREAD r11
mov r10, [r11 + OFFSET__Thread__m_alloc_context__alloc_limit]
mov rax, [r11 + OFFSET__Thread__m_alloc_context__alloc_ptr]
add rdx, rax
cmp rdx, r10
ja AllocFailed
mov [r11 + OFFSET__Thread__m_alloc_context__alloc_ptr], rdx
mov [rax], rcx
ret
AllocFailed:
jmp JIT_NEW
LEAF_END JIT_TrialAllocSFastMP_InlineGetThread, _TEXT
- 再調(diào)用構(gòu)造函數(shù)進(jìn)行值分配
在Example_12_1_4.Person..ctor()處設(shè)置斷點(diǎn)


快速路徑與慢速路徑
在上面提到過(guò)的JIT_TrialAllocSFastMP_InlineGetThread方法中,可以看到當(dāng)Alloc_limit不足,不能完成內(nèi)存分配時(shí),會(huì)執(zhí)行JIT_NEW方法。
JIT_NEW內(nèi)部有大量判斷,來(lái)盡最大可能保證分配成功。因此執(zhí)行速度比較慢,所以稱為慢速路徑,與之對(duì)應(yīng)的JIT_TrialAllocSFastMP_InlineGetThread方法,判斷極其簡(jiǎn)單且高效,所以被稱之為快速路徑
JIT在編譯期間會(huì)根據(jù)不同的對(duì)象來(lái)使用不同的策略,比如帶析構(gòu)函數(shù)的類默認(rèn)是慢速分配。
慢速分配流程圖如下:
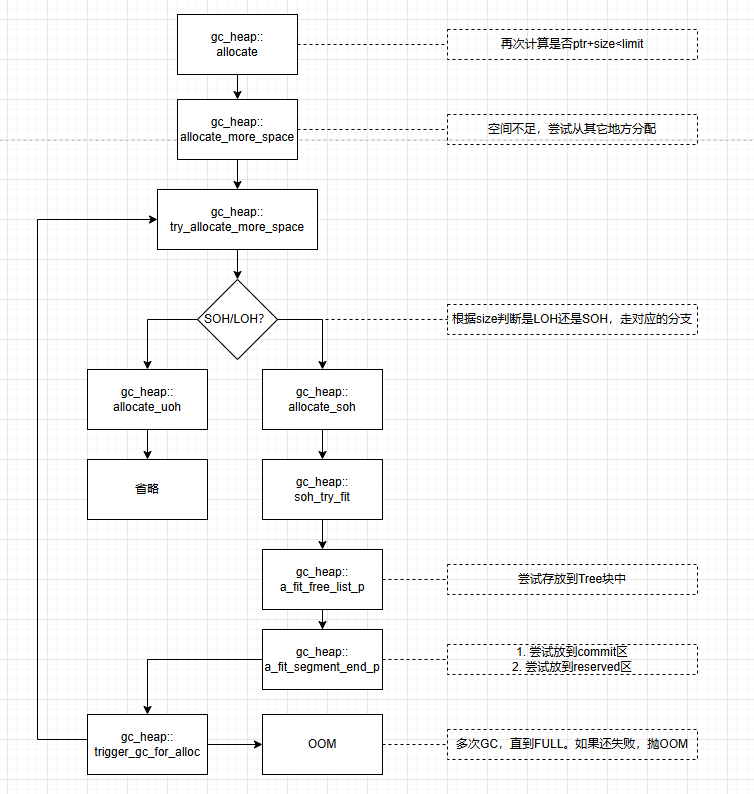
可以看到,快速分配僅僅用8行匯編就完成了分配過(guò)程,而慢速分配則復(fù)雜得多。
眼見為實(shí)
點(diǎn)擊查看代碼
internal class Program
{
static void Main(string[] args)
{
byte[] b = new byte[86000];
var p = new Person();
var pf = new PersonFinalize();
Debugger.Break();
}
}
public class Person
{
}
public class PersonFinalize
{
~PersonFinalize()
{
}
}
避免堆分配
到目前位置,我們討論都是在托管堆上的分配,也了解到.NET如何盡可能使堆分配更高效。
眾所周知,在棧上進(jìn)行分配與釋放的速度明顯要快得多,完全避免了堆過(guò)程。因此在特定條件下,棧分配是一個(gè)非常有空且高效的操作
如果我們希望非常高效地處理數(shù)據(jù)同時(shí)又不想再堆上分配大型數(shù)據(jù)表,可以顯示使用棧分配方式
棧分配方式主要有兩種:
- stackalloc
unsafe void Test()
{
int* array = stackalloc int[20];
array[0] = 10;
array[19] = 12;
Debugger.Break();
}
- Span
public void SpanTest()
{
Span<int> array = stackalloc int[20];
array[0] = 10;
array[19] = 12;
Debugger.Break();
}
顯式使用棧分配能帶來(lái)兩個(gè)好處
- 分配在棧上,永遠(yuǎn)不會(huì)進(jìn)入慢速分支,也完全不受GC管轄,但要注意StaticOverflow
- 由于生命周期跟隨棧指針,對(duì)象的地址也被變相的固定住(不會(huì)移動(dòng)),所以可以安全的將內(nèi)存地址傳遞給非托管代碼,且不會(huì)產(chǎn)生額外的固定(pinning)
固定(pinning)對(duì)象是影響GC速度的大殺手
總結(jié)
在性能要求非常高的情況下,盡量避免堆分配。如果條件允許,在棧上分配是更好的選擇,如果條件不允許(StaticOverflow),使用對(duì)象池機(jī)制實(shí)現(xiàn)對(duì)象復(fù)用也是一種好的解決辦法
基于這個(gè)思路,我們會(huì)發(fā)現(xiàn)日常編碼中,有很多值得優(yōu)化的地方
- 使用結(jié)構(gòu)傳遞小型數(shù)據(jù)
- 使用ValueTuple替代Tuple
- 使用stackalloc分配小型數(shù)組,或者使用ArrayPool實(shí)現(xiàn)對(duì)象復(fù)用
- 針對(duì)經(jīng)常被緩存的Task,使用ValueTask
- 閉包帶來(lái)的值類型提升
- 使用ValueTuple替代匿名對(duì)象
- ........................
晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")

