編碼揭秘:解構(gòu)字符%20背后的秘密與百分號(hào)編碼藝術(shù)
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
前言提到這個(gè) Unicode基礎(chǔ)知識(shí)Unicode 只是一個(gè)字符集, 其為每個(gè)字符提供了一個(gè)編號(hào),我們稱之為碼點(diǎn)。 Unicode 可以使用的編碼有三種,分別是: UFT-8:一種 所以UTF-8個(gè)UTF-16都屬于變長(zhǎng)編碼方案,而UTF-32屬于固定長(zhǎng)度編碼方案。 固定長(zhǎng)度編碼方案優(yōu)點(diǎn)當(dāng)然是簡(jiǎn)單啊,缺點(diǎn)嘛,費(fèi)空間, 這就是為嘛還要有UTF-16和UTF-8。 我們網(wǎng)絡(luò)傳輸常用 UTF-8, 而javascript運(yùn)行時(shí)的字符編碼是 UTF-16.
|
| 系列 | 保留字符 | 編碼 |
|---|---|---|
| escape | @ * _ + - . / | UTF-16 |
| encodeURI | - _ . ! ~ * ' ( ) ; , / ? : @ & = + $ # | UTF-8 |
| encodeURIComponent | - _ . ! ~ * ' ( ) | UTF-8 |
簡(jiǎn)單來說,escape是生成新的由十六進(jìn)制轉(zhuǎn)義序列替換的字符串,作用是讓它們?cè)谒须娔X上可讀。
編碼之后的效果是%XX或者%uXXXX這種形式。
當(dāng)你需要對(duì)URL編碼時(shí),請(qǐng)使用 encodeURI 或者 encodeURIComponent。
劃重點(diǎn): 基于UTF-16進(jìn)行編碼
UTF-16字符編碼,對(duì)于碼點(diǎn)大于0xFFFF的字符,其編碼結(jié)果是分高低位的, charCodeAt(0)可以獲得高位, charCodeAt(1)可以獲得低位。
轉(zhuǎn)義為兩個(gè)%uXXXX
先直接看代碼結(jié)果:
var ch = String.fromCodePoint(0x23455); // "??"
escape(ch) // '%uD84D%uDC55' 碼點(diǎn)大于 0xFFFF
unescape(escape(ch)) // "??"
ch.charCodeAt(0).toString(16).toUpperCase(); // 高位
// 'D84D'
ch.charCodeAt(1).toString(16).toUpperCase(); // 低位
// 'DC55'
看著結(jié)論就知道了,和charCodeAt的邏輯處理一致。 都是返回UTF-16編碼的高低位編碼。
由于 URL 只能由標(biāo)準(zhǔn) ASCII 字符組成,因此必須對(duì)其他特殊字符進(jìn)行編碼。它們將被代表 utf-8編碼的一系列不同字符所取代。
encodeURI 和 encodeURIComponent 用于此目的。
劃重點(diǎn),encodeURI 和 encodeURIComponent 采用的是UTF-8編碼。
先看看碼點(diǎn)和UTF-8編碼格式,以及需要的字節(jié)數(shù)。
| Unicode 碼點(diǎn)范圍(十六進(jìn)制) | 十進(jìn)制范圍 | UTF-8 編碼方式(二進(jìn)制) | 字節(jié)數(shù) |
|---|---|---|---|
0000 0000 ~ 0000 007F | 0 ~ 127 | 0xxxxxxx | 1 |
0000 0080 ~ 0000 07FF | 128 ~ 2047 | 110xxxxx 10xxxxxx | 2 |
0000 0800 ~ 0000 FFFF | 2048 ~ 65535 | 1110xxxx 10xxxxxx 10xxxxxx | 3 |
0001 0000 ~ 0010 FFFF | 65536 ~ 1114111 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 4 |
我們先看看 人 字:
4ebavar codePoint = "人".codePointAt(0).toString(16) // `4eba`
0000 0800 ~ 0000 FFFF, 格式為1110xxxx 10xxxxxx 10xxxxxx, 需要三個(gè)字節(jié)%XXencodeURI("人") // %E4%BA%BA
這里我們省略了具體的編碼過程, 具體的編碼結(jié)果驗(yàn)證可以去 Convert UTF8 to Binary Bits - Online UTF8 Tools 驗(yàn)證
最終編碼結(jié)果: 11100100 10111010 10111010
(0b11100100).toString(16).toUpperCase() // E4
(0b10111010).toString(16).toUpperCase() // BA
(0b10111010).toString(16).toUpperCase() // BA
encodeURI("人") // %E4%BA%BA => E4 BA BA
再推導(dǎo)一下??字
0x234550001 0000 ~ 0010 FFFF之間,格式為 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx, 需四個(gè)字節(jié)%XX組成encodeURI("??") // "%F0%A3%91%95"
既然有encodeURI為嘛還要來一個(gè)encodeURIComponent呢?
其用于對(duì)地址后的 參數(shù)值進(jìn)行編碼, 我們通常稱呼為queryString。
看個(gè)例子:
var param = "http://www.yyy.com"; //param為參數(shù)
param = encodeURIComponent(param);
var url = "http://www.xxxx.com?target=" + param;
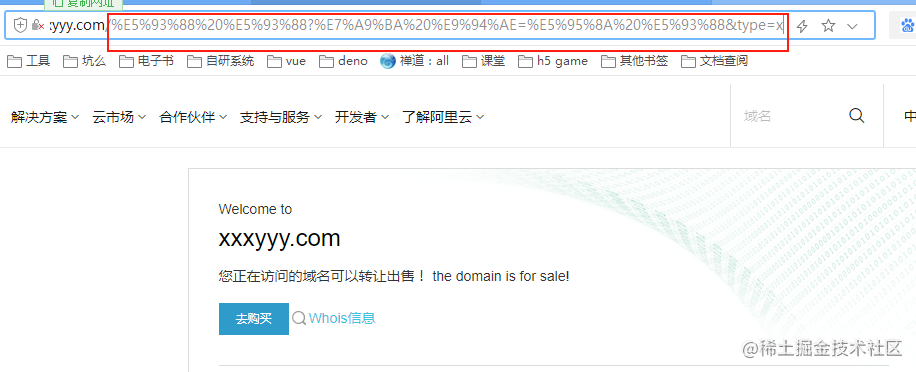
同理下面的?之后的部分空 鍵=啊 哈&type=x,鍵值對(duì)均需要encodeURIComponent進(jìn)行編碼。
http://wwww.xxxyyy.com/哈 哈?空 鍵=啊 哈&type=x
其實(shí)吧,現(xiàn)代瀏覽器,默認(rèn)都會(huì)自行進(jìn)行編碼,你不妨把上面的地址貼到瀏覽器:
對(duì)于 application/x-www-form-urlencoded (POST) 這種數(shù)據(jù)方式, 也是需要編碼的。
其編碼規(guī)則:
'&' 分隔的鍵-值對(duì), 同時(shí)以 '=' 分隔鍵和值.我們先一起看看 percent-encoding(百分號(hào)編碼)。
百分比編碼(也有叫百分號(hào)編碼的) 是一種擁有8位字符編碼的編碼機(jī)制,這些編碼在URL的上下文中具有特定的含義。它有時(shí)被稱為URL編碼。編碼由英文字母替換組成:“%” 后跟替換字符的ASCII的十六進(jìn)制表示。
它廣泛地應(yīng)用于主統(tǒng)一資源標(biāo)志符/統(tǒng)一資源定位符集(URI) ,其中包括 URL 和統(tǒng)一資源名(URN)。
它還用于準(zhǔn)備應(yīng)用 application/x-www-form-urlencoded 媒體類型的數(shù)據(jù),這通常用于在 HTTP 請(qǐng)求中提交 HTML 表單數(shù)據(jù)。
URI所允許的字符分作保留與未保留。保留字符是那些具有特殊含義的字符,例如:斜線字符用于URL(或URI)不同部分的分界符;未保留字符沒有這些特殊含義。百分號(hào)編碼把保留字符表示為特殊字符序列。
保留字符需要編碼,其有: ':','/','?','#','[',']','@','!','$','&',"'",'(',')','*','+',',',';','=',以及,'%' 本身, 以及一個(gè)空格 " "。
percent-encoding編碼對(duì)照表請(qǐng)參見:percent-encoding | MDN
不需要被編碼,直接使用就行。
- _ . ~" ",%20+那么,我們這里直接使用 encodeURLComponent編碼值和鍵,能行嗎?
答案是不行:
百分比編碼需要編碼特殊字符的是 20個(gè)(加上 ' ')
: / ? # [ ] @ ! $ & ' ( ) * + , ; = %
encodeURLComponent不編碼的字符是 9 個(gè):
- _ . ! ~ * ' ( )
所以還需要額外編碼為: ['!', "'", '(', ')', '*'], 怎么計(jì)算而得,參見下面代碼:
var percentChars = [':', '/', '?', '#', '[', ']', '@', '!', '$', '&', "'", '(', ')', '*', '+', ',', ';', '=', '%', ' '];
var eURICChars = ['-', '_', '.', '!', '~', '*', "'", '(', ')'];
var notInPChars = percentChars.filter(c=> eURICChars.includes(c));
console.log("notInPChars:", notInPChars);
// notInPChars: (5) ['!', "'", '(', ')', '*']
所以,完整的編碼應(yīng)該如下:
function encodeValue(val)
{
var eVal = encodeURIComponent(val);
// 單獨(dú)處理encodeURIComponent不編碼的字符
eVal = eVal.replace(/\*/g, '%2A');
eVal = eVal.replace(/!/g, '%21');
eVal = eVal.replace(/\(/g, '%28');
eVal = eVal.replace(/\)/g, '%29');
eVal = eVal.replace(/'/g, '%27');
// 特殊處理空格字符
return eVal.replace(/\%20/g,'+');
}
我們后臺(tái)返回文件的時(shí)候,如果指定Content-Disposition: attachment并設(shè)定好filename, 客戶端收到請(qǐng)求后是可以直接進(jìn)行文件下載的。 問題就在于這個(gè)filename,其也是需要被編碼的,我們了解一下即可:
參考MDN:
var fileName = 'my file(2).txt';
var header = "Content-Disposition: attachment; filename*=UTF-8''"
+ encodeRFC5987ValueChars(fileName);
console.log(header);
// 輸出 "Content-Disposition: attachment; filename*=UTF-8''my%20file%282%29.txt"
function encodeRFC5987ValueChars (str) {
return encodeURIComponent(str).
// 注意,盡管 RFC3986 保留 "!",但 RFC5987 并沒有
// 所以我們并不需要過濾它
replace(/['()]/g, escape). // i.e., %27 %28 %29
replace(/\*/g, '%2A').
// 下面的并不是 RFC5987 中 URI 編碼必須的
// 所以對(duì)于 |`^ 這3個(gè)字符我們可以稍稍提高一點(diǎn)可讀性
replace(/%(?:7C|60|5E)/g, unescape);
}
其比 percent-encoding又還有些區(qū)別,注釋里面寫得很清楚。 我真想說,搞那么多協(xié)議不累嗎?
看到注冊(cè),我們可以看到 RFC3986, RFC5987等協(xié)議,我們一起了解一下。
RFC3986, RFC1738是關(guān)于URI的編碼規(guī)范,RFC5987是關(guān)于http協(xié)議文件頭字段的規(guī)范。
RFC3986
2005年發(fā)布,現(xiàn)行標(biāo)準(zhǔn)。文檔對(duì)URL的編解碼問題做出了詳細(xì)的建議,指出了哪些字符需要被編碼才不會(huì)引起Url語義的轉(zhuǎn)變,以及對(duì)為什么這些字符需要編碼做出了相應(yīng)的解釋
RFC 1738
94年發(fā)布。同上。
RFC5987
Character Set and Language Encoding for Hypertext Transfer Protocol (HTTP) Header Field Parameters。 翻譯: 超文本傳輸協(xié)議文件頭字段參數(shù)的字符集和語言編碼, 對(duì)http傳輸頭部字符串編碼的規(guī)范。
你會(huì)發(fā)現(xiàn)很多代碼還會(huì)處理~符號(hào),雖然RFC3986文檔規(guī)定,對(duì)于波浪符號(hào)~,不需要進(jìn)行Url編碼,但是還是有很多老的網(wǎng)關(guān)或者傳輸代理。
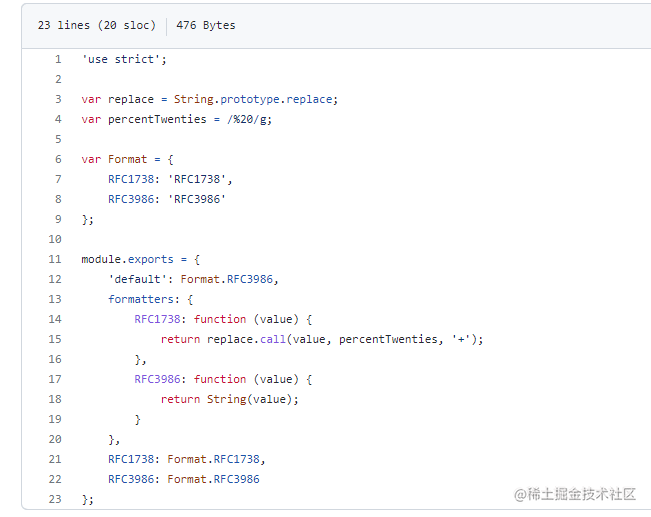
兼容性好的代碼,會(huì)兼容處理 RFC1738, 比如著名的qs庫的 formats.js
window.btoa可以進(jìn)字符進(jìn)行base64編碼, window.atob可以解碼。
window.btoa("abcd") // "YWJjZA=="
window.atob("YWJjZA==") // "abcd"
但是其職能編碼ASCII 字符串, 試試中文:
window.btoa("人")
// Uncaught DOMException: Failed to execute 'btoa' on 'Window':
// The string to be encoded contains characters outside of the Latin1 range.
怎么解決呢?
// ucs-2 string to base64 encoded ascii
function utoa(str) {
return window.btoa(unescape(encodeURIComponent(str)));
}
// base64 encoded ascii to ucs-2 string
function atou(str) {
return decodeURIComponent(escape(window.atob(str)));
}
驗(yàn)證一下, 完美。
utoa("人") //5Lq6
atou("5Lq6") //人
那么這是什么思路呢???
encodeURIComponent 將字符轉(zhuǎn)為百分比utf-8字節(jié)存儲(chǔ)為% XX 之后,unescape 將它們轉(zhuǎn)換為 btoa 所要求的單個(gè)代碼點(diǎn)。因此,btoa (unescape (encodeURIComponent (str)))都將文本編碼為 utf-8字節(jié),然后將其編碼為 Base64。
雖然,你去掉中間的unescape和escape也可以正常使用,但是必須搭配使用啦。
但是,已經(jīng)不是標(biāo)準(zhǔn)的utf-8轉(zhuǎn)為Base64了。
自己玩:
window.btoa(encodeURIComponent("我是人a"))
// JUU2JTg4JTkxJUU2JTk4JUFGJUU0JUJBJUJBYQ==
decodeURIComponent(window.atob("JUU2JTg4JTkxJUU2JTk4JUFGJUU0JUJBJUJBYQ=="))
// 我是人a
標(biāo)準(zhǔn)base解碼,已經(jīng)得不到正確結(jié)果: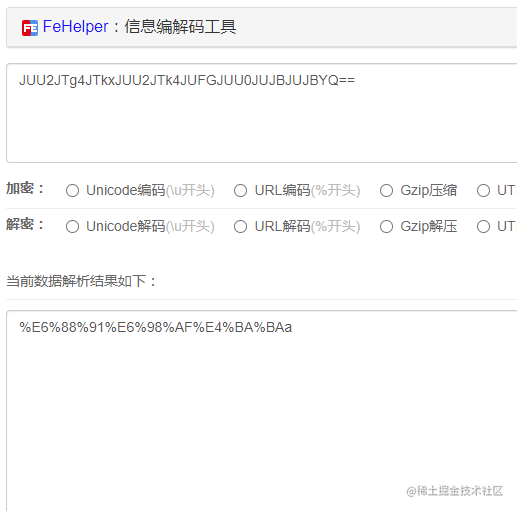
%20 是escape或者URL編碼得到的結(jié)果,對(duì)應(yīng)著空字符 " "。 也可是說是百分號(hào)編碼。?轉(zhuǎn)自https://www.cnblogs.com/cloud-/p/18095685
晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲(chǔ)管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")

