阿里半夜開源全新推理模型,QwQ-32B比肩DeepSeek-R1滿血版
當(dāng)前位置:點(diǎn)晴教程→知識管理交流
→『 技術(shù)文檔交流 』
3月6日凌晨 3 點(diǎn),阿里開源發(fā)布了新推理模型 QwQ-32B,其參數(shù)量為 320 億,但性能足以比肩 6710 億參數(shù)的 DeepSeek-R1 滿血版。
千問的推文表示:「這次,我們研究了擴(kuò)展 RL 的方法,并基于我們的 Qwen2.5-32B 取得了一些令人印象深刻的成果。我們發(fā)現(xiàn) RL 訓(xùn)練可以不斷提高性能,尤其是在數(shù)學(xué)和編碼任務(wù)上,并且我們觀察到 RL 的持續(xù)擴(kuò)展可以幫助中型模型實(shí)現(xiàn)與巨型 MoE 模型相媲美的性能。歡迎與我們的新模型聊天并向我們提供反饋!」 QwQ-32B 已在 Hugging Face 和 ModelScope 開源,采用了 Apache 2.0 開源協(xié)議。大家也可通過 Qwen Chat 直接進(jìn)行體驗(yàn)!
本地部署工具 Ollama 也第一時間提供了支持:ollama run qwq
千問官方發(fā)布了題為「QwQ-32B: 領(lǐng)略強(qiáng)化學(xué)習(xí)之力」的官方中文博客介紹這一吸睛無數(shù)的進(jìn)展。考慮到強(qiáng)化學(xué)習(xí)之父 Richard Sutton 與導(dǎo)師 Andrew Barto 剛剛獲得圖靈獎,QwQ-32B 的發(fā)布可說是非常應(yīng)景。
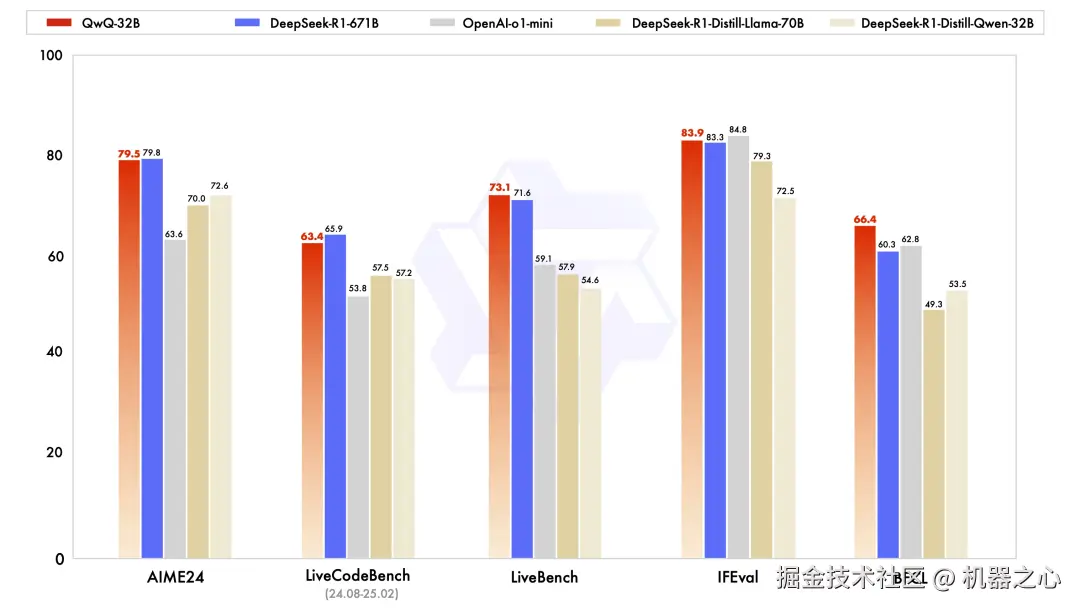
博客中寫到,大規(guī)模強(qiáng)化學(xué)習(xí)(RL)非常具有潛力,在提升模型性能方面可望超越傳統(tǒng)的預(yù)訓(xùn)練和后訓(xùn)練方法。 近期的研究表明,強(qiáng)化學(xué)習(xí)可以顯著提高模型的推理能力。例如,DeepSeek-R1 通過整合冷啟動數(shù)據(jù)和多階段訓(xùn)練,實(shí)現(xiàn)了最先進(jìn)的性能,使其能夠進(jìn)行深度思考和復(fù)雜推理。 而千問團(tuán)隊(duì)則探索了大規(guī)模強(qiáng)化學(xué)習(xí)(RL)對大語言模型的智能的提升作用,推理模型 QwQ-32B 便由此而生。 這是一款擁有 320 億參數(shù)的模型,其性能可媲美具備 6710 億參數(shù)(其中 370 億被激活)的 DeepSeek-R1。該團(tuán)隊(duì)表示:「這一成果突顯了將強(qiáng)化學(xué)習(xí)應(yīng)用于經(jīng)過大規(guī)模預(yù)訓(xùn)練的強(qiáng)大基礎(chǔ)模型的有效性。」 QwQ-32B 中還集成了與 Agent(智能體)相關(guān)的能力,使其能夠在使用工具的同時進(jìn)行批判性思考,并根據(jù)環(huán)境反饋調(diào)整推理過程。該團(tuán)隊(duì)表示:「我們希望我們的一點(diǎn)努力能夠證明強(qiáng)大的基礎(chǔ)模型疊加大規(guī)模強(qiáng)化學(xué)習(xí)也許是一條通往通用人工智能的可行之路。」 模型效果 QwQ-32B 在一系列基準(zhǔn)測試中進(jìn)行了評估,包括數(shù)學(xué)推理、編程和通用能力。以下結(jié)果展示了 QwQ-32B 與其他領(lǐng)先模型的性能對比,包括 DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini 以及原始的 DeepSeek-R1。
可以看到,QwQ-32B 的表現(xiàn)非常出色,在 LiveBench、IFEval 和 BFCL 基準(zhǔn)上甚至略微超過了 DeepSeek-R1-671B。 強(qiáng)化學(xué)習(xí) QwQ-32B 的大規(guī)模強(qiáng)化學(xué)習(xí)是在冷啟動的基礎(chǔ)上開展的。 在初始階段,先特別針對數(shù)學(xué)和編程任務(wù)進(jìn)行 RL 訓(xùn)練。與依賴傳統(tǒng)的獎勵模型(reward model)不同,千問團(tuán)隊(duì)通過校驗(yàn)生成答案的正確性來為數(shù)學(xué)問題提供反饋,并通過代碼執(zhí)行服務(wù)器評估生成的代碼是否成功通過測試用例來提供代碼的反饋。 隨著訓(xùn)練輪次的推進(jìn),QwQ-32B 在這兩個領(lǐng)域中的性能持續(xù)提升。 在第一階段的 RL 過后,他們又增加了另一個針對通用能力的 RL。此階段使用通用獎勵模型和一些基于規(guī)則的驗(yàn)證器進(jìn)行訓(xùn)練。結(jié)果發(fā)現(xiàn),通過少量步驟的通用 RL,可以提升其他通用能力,同時在數(shù)學(xué)和編程任務(wù)上的性能沒有顯著下降。 API 如果你想通過 API 使用 QwQ-32B,可以參考以下代碼示例:
未來工作 千問團(tuán)隊(duì)還在博客中分享了未來計(jì)劃,其中寫到:「這是 Qwen 在大規(guī)模強(qiáng)化學(xué)習(xí)(RL)以增強(qiáng)推理能力方面的第一步。通過這一旅程,我們不僅見證了擴(kuò)展 RL 的巨大潛力,還認(rèn)識到預(yù)訓(xùn)練語言模型中尚未開發(fā)的可能性。在致力于開發(fā)下一代 Qwen 的過程中,我們相信將更強(qiáng)大的基礎(chǔ)模型與依托規(guī)模化計(jì)算資源的 RL 相結(jié)合,將會使我們更接近實(shí)現(xiàn)人工通用智能(AGI)。此外,我們正在積極探索將智能體與 RL 集成,以實(shí)現(xiàn)長時推理,目標(biāo)是通過推理時間擴(kuò)展來釋放更高的智能。」 QwQ-32B 收獲無數(shù)好評 QwQ-32B 一發(fā)布就收獲了無數(shù)好評,甚至我們的不少讀者也在催促我們趕緊報道。 在前段時間的 DeepSeek 熱潮中,大家都熱衷于討論滿血版,因?yàn)檎麴s版性能受限。但是 671B 的滿血版模型無法輕易部署,普通的端側(cè)設(shè)備只能退而求其次。現(xiàn)在,Qwen 把模型大小打下來了,端側(cè)有希望了嗎?
有網(wǎng)友表示,手機(jī)上肯定還不行,但運(yùn)行內(nèi)存比較高的 Mac 或許可以一戰(zhàn)。
還有人喊話阿里巴巴通義實(shí)驗(yàn)室科學(xué)家 Binyuan Hui 去做更小的模型。
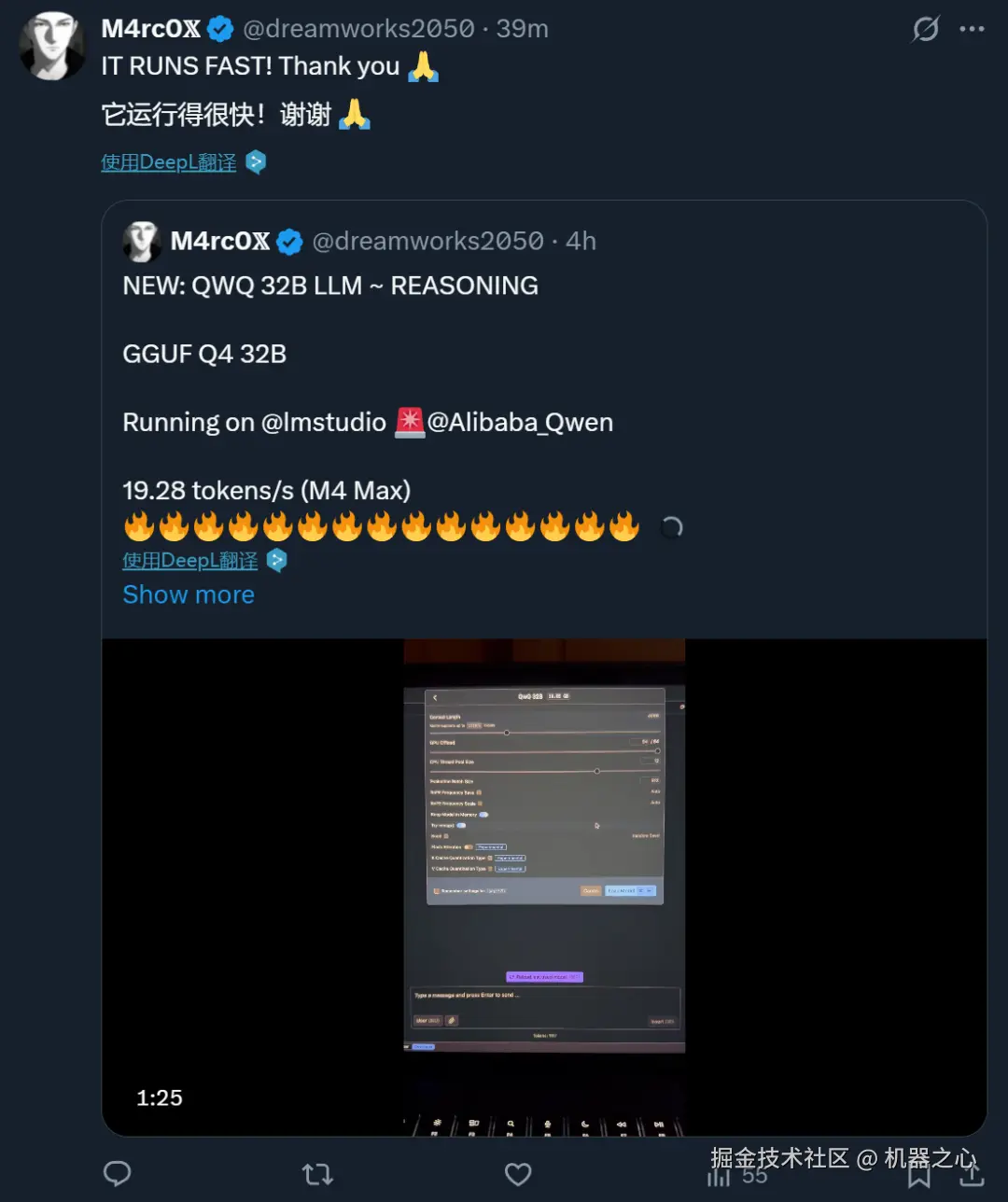
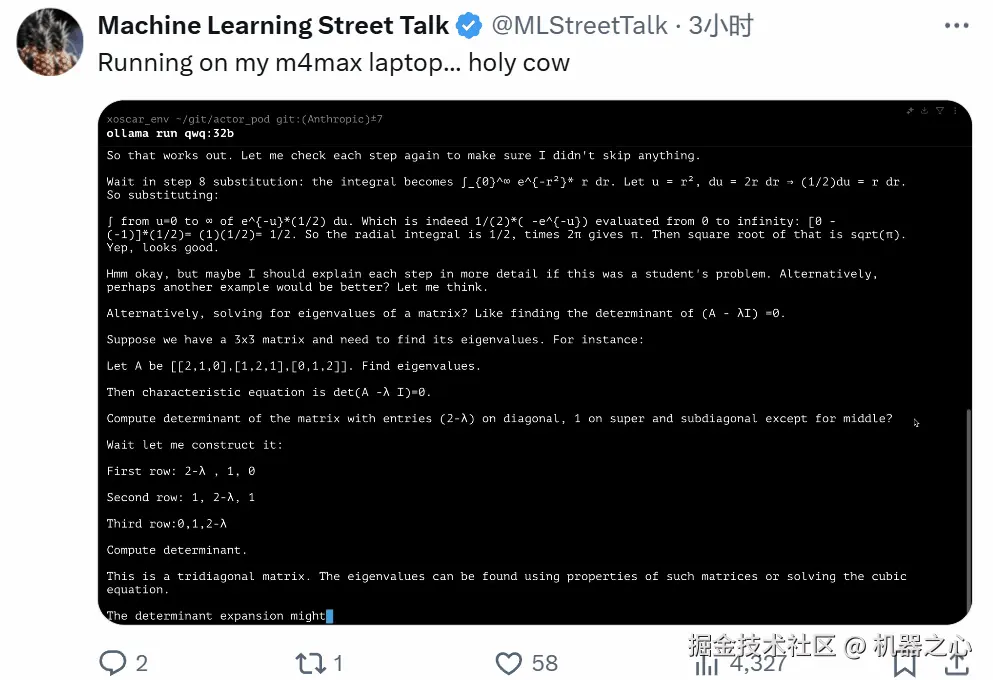
還有人曬出體驗(yàn),表示運(yùn)行很快:
蘋果機(jī)器學(xué)習(xí)研究者 Awni Hannun 也同樣已經(jīng)在 M4 Max 上成功運(yùn)行了 QwQ-32B,看起來速度非常快。
在 Qwen 的官方聊天界面(Qwen Chat),我們已經(jīng)能看到 QwQ-32B 的預(yù)覽版模型。感興趣的讀者可以前去測試。
測試鏈接:chat.qwen.ai/ 作者:機(jī)器之心 鏈接:https://juejin.cn/post/7478513497456541737 來源:稀土掘金 著作權(quán)歸作者所有。商業(yè)轉(zhuǎn)載請聯(lián)系作者獲得授權(quán),非商業(yè)轉(zhuǎn)載請注明出處。 該文章在 2025/4/3 15:01:37 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉儲管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")